728x90
본격적으로 데이터 분석을 하기 위해 Numpy와 Pansdas를 사용해보겠다.
둘다 초면이다.
Numpy
: Numerical Python 수치적 파이썬이란 뜻으로 파이썬에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리다. 반복문 없이 배열을 처리할 수 있고, 빠른 연산과 메모리를 효율적으로 사용할 수 있다.
Pandas
: 파이썬 라이브러리 중 하나로 구조화된 데이터를 효과적으로 처리하며 저장하고 Numpy와 함께 사용
import numpy as np
import pandas as pd
country = pd.Series([5180,12718,141500,32676], index = ['korea', 'japan', 'china', 'usa'], name="country")
print(country, "\n")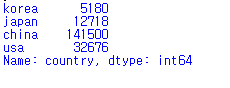
데이터 프레임
: 여러 개의 Series가 모여서 행과 열을 이룬 데이터, Dictionary를 활용해서 데이터 프레임 생성 가능
import numpy as np
import pandas as pd
# 두 개의 시리즈 데이터가 있습니다.
print("Population series data:")
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676
}
population = pd.Series(population_dict)
print(population, "\n")
print("GDP series data:")
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
print(gdp, "\n")
# 이곳에서 2개의 시리즈 값이 들어간 데이터프레임을 생성합니다.
print("Country DataFrame")
country = pd.DataFrame({
"population" : population,
"gdp" : gdp
})
print(country)
데이터 프레임에서 원하는 데이터만 출력하고 싶으면 다음과 같이 사용할 수 있다.
import numpy as np
import pandas as pd
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676
}
population = pd.Series(population_dict)
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
country = pd.DataFrame({
"population" : population,
"gdp" : gdp
})
# loc 을 활용하여 'korea' 행의 데이터를 출력하세요.
print('=== Korea ===')
print(country.loc['korea'])
print('')
# loc 을 활용하여 'korea', 'japan', 'china' 행의 데이터를 출력하세요.
print('=== Korea, Japan, China ===')
print(country.loc['korea':'china']) # korea ~ china
print('')
# iloc 을 활용하여 'korea', 'japan', 'china' 행의 데이터를 출력하세요.
print('=== Korea, Japan, China ===')
print(country.iloc[ 0 : 3 ]) # 0-th ~ 2-nd -> [0:3]
print('')
# iloc 을 활용하여 모든 나라의 'gdp' 열의 데이터를 출력하세요.
print('=== GDP ===')
print(country.iloc[:, 1 ]) # population는 0-th 열, gdp는 1-st 열
print('')
# 컬럼명을 활용하여 모든 나라의 'population' 데이터를 출력하세요.
print('=== population ===')
print(country['population'])
print('')
Matplotlib로는 그래프를 만들 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.arange(10)
fig, ax = plt.subplots()
ax.plot(
x, x, label='y=x',
linestyle='-',
marker='.',
color='blue'
)
ax.plot(
x, x**2, label='y=x^2',
linestyle='-.',
marker=',',
color='red'
)
ax.set_xlabel("x")
ax.set_ylabel("y")
fig.savefig("plot.png")
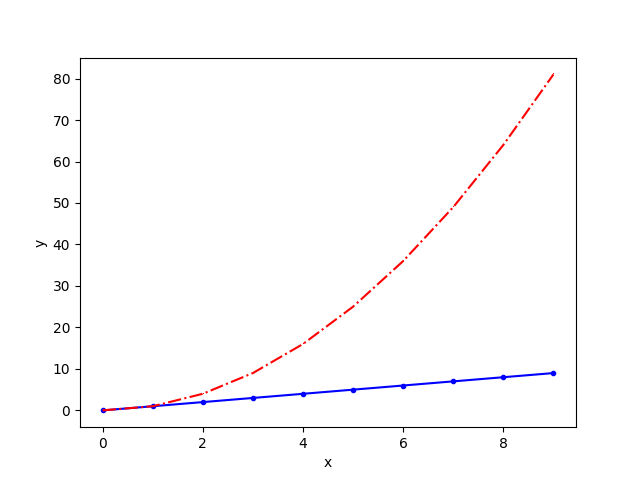
Line Style
| 기호 | 의미 |
| - | 실선 |
| – | 대시 선 |
| -. | 대시 점선 |
| : | 점선 |
Markers
| 기호 | 의미 | 기호 | 의미 |
| . | 점 | , | 픽셀 |
| o | 원 | s | 사각형 |
| v, <, ^, > | 삼각형 | 1, 2, 3, 4 | 삼각선 |
| p | 오각형 | H, h | 육각형 |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.arange(10)
fig, ax = plt.subplots()
ax.plot(x, x, linestyle="-", marker =".")
ax.plot(x, x+2, linestyle="--", marker ="*")
ax.plot(x, x+4, linestyle="-.", marker ="o")
ax.plot(x, x+6, linestyle=":", marker ="s")
fig.savefig("plot.png")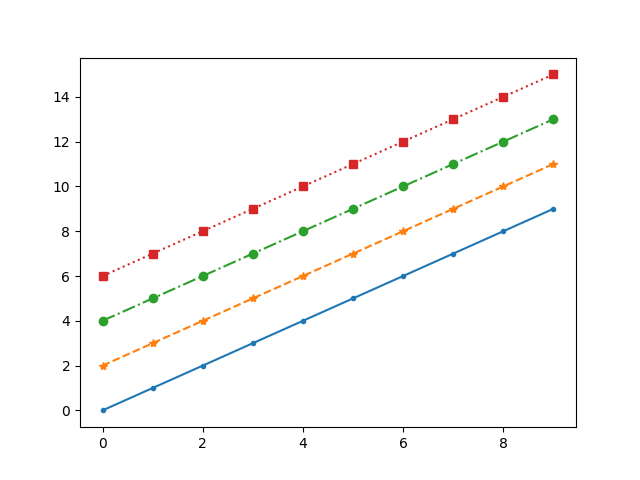
삼각함수도 만들 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 1000)
fig, ax = plt.subplots()
ax.plot(x, np.sin(x))
ax.set_xlim(-2, 12)
ax.set_ylim(-1.5, 1.5)
fig.savefig("plot.png")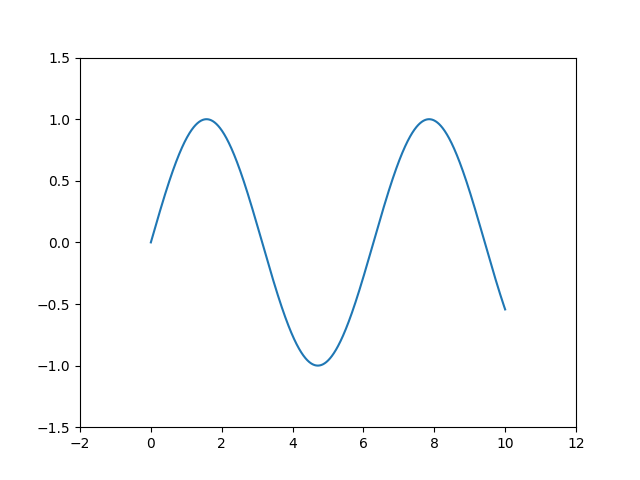
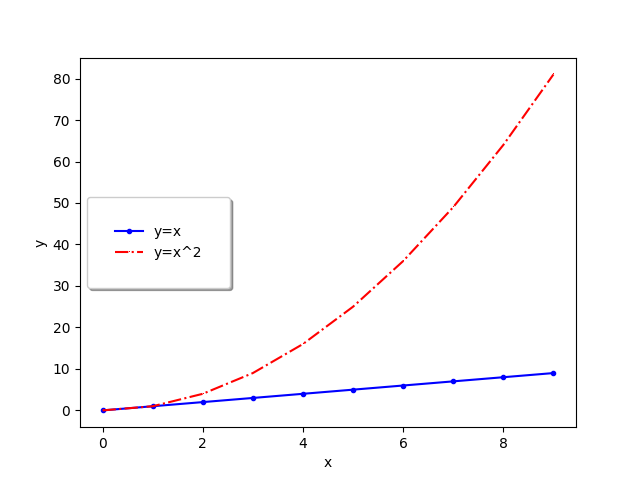
함수에 대해 설명하는 박스도 만들 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.arange(10)
fig, ax = plt.subplots()
ax.plot(
x, x, label='y=x',
linestyle='-',
marker='.',
color='blue'
)
ax.plot(
x, x**2, label='y=x^2',
linestyle='-.',
marker=',',
color='red'
)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(
loc='center left',
shadow=True,
fancybox=True,
borderpad=2
)
fig.savefig("plot.png")
막대그래프나 히스토그램도 제작할 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
fname='./NanumBarunGothic.ttf'
font = fm.FontProperties(fname = fname).get_name()
plt.rcParams["font.family"] = font
# Data set
x = np.array(["축구", "야구", "농구", "배드민턴", "탁구"])
y = np.array([13, 10, 17, 8, 7]) # [13, 10, 17, 8, 7] 로 변경해보세요.
z = np.random.randn(1000)
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
# Bar 그래프
axes[0].bar(x, y)
# 히스토그램
axes[1].hist(z, bins = 200) # bins를 200으로 변경해보세요.
# elice에서 그래프 확인하기
fig.savefig("plot.png")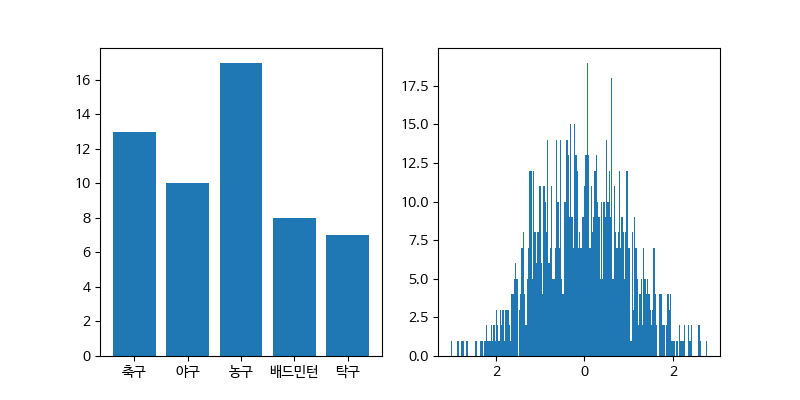
참고로 엘리스 코딩에서 무료로 해주는 AI 데이터 분석 수업에서 대부분 자료를 가지고 왔다.
728x90
'미쳤습니까 휴먼 (AI)' 카테고리의 다른 글
| [인공지능] 퍼셉트론 (0) | 2024.12.04 |
|---|---|
| [인공지능] 지식 표현과 추론 (1) | 2024.12.02 |
| [인공지능] 탐색과 최적화 (0) | 2024.12.02 |
| [인공지능] 인공지능이란? (0) | 2024.09.21 |
| [AI 데이터 분석] 파이썬 모듈과 패키지 (0) | 2022.08.24 |


