
데이터 주도 학습
학습 (learning): 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
기계학습 :
- 데이터에서 답을 찾고 데이터에서 패턴을 발견하고 데이터로 이야기를 만듦
- 사람의 개입을 최소화하고 수집한 데이터로부터 패턴을 찾으려 시도함
종단간 기계학습(end-to-end machine learning)
- 기계학습: 데이터의 특징을 벡터로 변환하는 것은 ‘사람’이 설계함
- 딥러닝: 데이터 입력에서 목표한 결과를 사람의 개입 없이 얻음

훈련데이터(training data): 최적의 매개변수 탐색하는데 사용됨
시험데이터(test data): 훈련한 모델의 성능을 평가하는데 사용됨
훈련데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가
과소적합(Underfitting)
- 높은 편향(bias)을 가진 경우의 일반적인 학습 곡선.
- 편향: 예측 모델이 학습 데이터에 대해 평균적으로 얼마나 잘 맞는지를 나타냄.
- 높은 편향: 학습은 빠르고 이해하기 쉬우나, 모델의 유연성이 떨어져 복잡한 패턴을 제대로 학습하지 못함.
과대적합(Overfitting)
- 높은 분산(variance)을 가진 경우의 일반적인 학습 곡선.
- 분산: 동일한 모델에서 또는 다른 모델 간에 예측 값이 데이터 세트에 의해 얼마나 영향을 받는지를 나타냄.
- 높은 분산: 모델이 데이터 세트의 값에 크게 영향을 받아 새로운 데이터에 대해 일반화가 잘 되지 않음.



- 신경망 학습에 사용하는 지표
- 신경망 성능의 ‘나쁨’을 나타내는 지표
- 현재의 신경망이 훈련데이터를 얼마나 잘 처리하지 못하느냐를 나타냄
- 평균제곱오차와 교차 엔트로피 오차를 일반적으로 사용함
One-hot encoding (원-핫 인코딩) : 데이터를 쉽게 중복 없이 표현할 때 사용하는 형식
- 각 단어에 고유한 인덱스 부여
- 표현하고 싶은 단어의 인덱스 위치에 1을 부여, 다른 단어의 인덱스 위치 에는 0을 부여
평균 제곱 오차 (mean squared error, MSE)

교차 엔트로피 오차 (cross-entropy error, CEE)

미니배치 학습
- 기계학습: 훈련데이터에 대한 손실 함수의 값을 구하고, 그 값을 최대한 줄 여주는 매개변수를 찾아냄
- 모든 훈련데이터를 대상으로 손실 함수 값을 구한 후 평균을 구함
- 미니배치(mini-batch): 데이터 일부를 추려 전체의 ‘근사치’로 이용할 수 있 음
- 미니배치 학습: 60,000장의 훈련 데이터 중 100장을 무작위로 뽑아 그 100장 만을 사용하여 학습함

손실함수를 지표로 삼는 이유
- 정확도를 학습 지표로 사용하면, 정확도를 높이더라도 값이 불연속적으로 변하기 때문에 매개변수의 세부 조정에 대한 효과를 확인하기 어려움.
- 예를 들어, 100개의 데이터 중 32개를 맞춘 모델에서 조금 더 학습해 34개, 35개를 맞췄다 하더라도 값이 단계적으로만 변화함
- 반면, 손실함수는 매개변수의 작은 변화가 성능에 미치는 영향을 연속적으로 측정할 수 있음
손실함수와 미분
- 손실함수는 미분을 통해 매개변수 조정 방향과 크기를 결정할 수 있음
- 미분값 < 0: 매개변수를 양의 방향으로 조정 → 손실함수 값을 감소
- 미분값 > 0: 매개변수를 음의 방향으로 조정 → 손실함수 값을 감소
- 미분값 = 0: 손실함수가 더 이상 변화하지 않으므로 갱신을 멈춤

수치 미분 : 아주 작은 값을 주었을 때의 차분으로 미분하는 것, 수치 미분을 이용해 가중치 매개변수의 기울기를 구할 수 있음
- 미분(differentiation) : ‘특정 순간’의 변화량, 어떤 값이 변할 때 다른 값이 얼마나 빨리 변하는지를 나타내는 것
- 중심 차분(central difference) : x를 중심으로 그 전후의 차분 계산
- 전방 차분(forward difference) : (x+h) – (x)
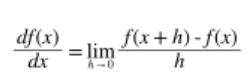

- 편미분 : 변수가 여럿인 함수에 대한 미분
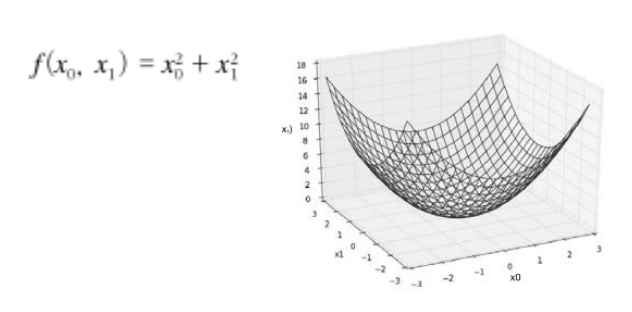
기울기
기울기 : 모든 변수의 편미분을 벡터로 정리한 것

경사하강법 (Gradient Descent Method) : 매개변수 공간에서 손실 함수의 최소값을 찾기 위해 기울기를 이용

- 학습률 (Learning Rate):
- 매개변수를 한 번에 얼마나 갱신할지 결정
- 너무 크면 발산하거나 진동하며 수렴되지 않음
- 너무 작으면 학습이 느리거나 제대로 수렴하지 않음
- 하이퍼파라미터 (Hyperparameter)
- 사람이 직접 설정해야 하는 매개변수
- 실험적으로 반복하며 최적의 값을 찾아야 함

기울기 (Gradient)
- 신경망에서의 기울기: 가중치 매개변수에 대한 손실 함수의 기울기
- 최적화: 손실 함수가 최소값이 되는 매개변수(가중치와 편향)를 찾는 과정

Gradient Descent vs. Gradient Ascent
- Gradient Descent: 최소값을 찾는 방법
- Gradient Ascent: 최대값을 찾는 방법

학습 알고리즘 구현
전제 : 신경망은 가중치와 편향을 훈련 데이터에 적합하게 조정하는 학습 과정을 통해 최적화됨
- 미니배치 선정
- 훈련 데이터 중 일부를 무작위로 추출해 미니배치를 구성
- 목표: 미니배치의 손실 함수 값을 줄이는 것
- 기울기 산출
- 미니배치의 손실 함수를 기반으로 각 가중치 매개변수의 기울기 계산.
- 기울기는 손실 함수를 최소화하는 방향을 알려줌.
- 매개변수 갱신
- 가중치 매개변수를 기울기의 반대 방향으로 조금씩 조정.
- 반복
- 위 1~3단계를 반복 수행
평가와 에폭
- 에폭(Epoch): 학습에서 전체 훈련 데이터를 한 번 모두 사용하는 것.
- 10,000개의 훈련 데이터를 100개씩 미니배치로 학습 → 100번 반복 시 1에폭.
- 학습이 잘 진행되면 손실 함수 값이 점진적으로 감소하며, 신경망이 데이터를 잘 학습하고 있다는 것을 의미.

시험 데이터로 평가
- 학습된 신경망을 시험 데이터에 적용해 성능을 평가.
- 학습 데이터에만 과적합되지 않고, 일반화 능력을 확인.
'미쳤습니까 휴먼 (AI)' 카테고리의 다른 글
| [인공지능] 학습 관련 기술들 (1) | 2024.12.05 |
|---|---|
| [인공지능] 오차역전파법 (0) | 2024.12.04 |
| [인공지능] 신경망 (0) | 2024.12.04 |
| [인공지능] 퍼셉트론 (0) | 2024.12.04 |
| [인공지능] 지식 표현과 추론 (1) | 2024.12.02 |